¶ Create a backend library
A backend library is used on the server and is the corresponding counterpart of a frontend library on the backend side. (see Yoeman-Generator).
As an example we show how a db connector can be generated.
¶ Goals
In this tutorial you will learn how to create a server plugin and register a new database connector for the TDP platform.
¶ Prerequisites
This tutorial requires you to complete the following steps / tutorials (with links):
¶ Summary
# switch to the workspace directory
cd <workspace directory>
# download https://drive.google.com/uc?export=download&id=0B7ArG7ViwFynb2JzYnQ4NUg0TEE
# and put it under _data/mydb.sqlite
mkdir myserverlugin
cd myserverplugin
yo phovea:init-slib
git add -A
git commit -m 'Initial Commit'
yo phovea:add-extension
# see below
# edit myserverplugin/db.py
# edit myserverplugin/config.json
cd ..
docker-compose restart api
# http://localhost:8080/api/tdp/db/mydb/
http://localhost:8080/api/tdp/db/mydb/mytable returns our table with records of the following format
{
"_id": 0,
"id": 1,
"name": "My 1",
"value": 372,
"cat": "MyCat 4",
"my_id": 1
}
¶ Tutorial
¶ Prepare database
In this tutorial we are going to integrate a small test database which is an extension to the tdp_dummy database.
We use an SQLite database backend since it doesn’t require any additional installations. The database file is located at: mydb.sqlite. Download this file and store it at: <workspace location>/_data/mydb.sqlite if the _data folder doesn’t exist please create it.
The data model of this database is very simple. It just contains two tables: mytable and mytable_scores.
The tables were created using the following script and populated with random data:
CREATE TABLE "mytable" (
"my_id" VARCHAR PRIMARY KEY NOT NULL,
"name" VARCHAR,
"cat" VARCHAR, -- categorical: MyCat 1, MyCat 2, MyCat 3, MyCat 4
"value" INTEGER -- range: 0 ... 1000
);
CREATE TABLE "mytable_scores" (
"my_id" VARCHAR NOT NULL,
"a_id" VARCHAR NOT NULL,
"value" INTEGER, -- range: 0 ... 100
PRIMARY KEY ("my_id", "a_id")
);
The table mytable_scores is a matrix of mytable ids with a ids as used by the tdp_dummy plugin database. This will allow us to create scores for mytable to a and vice versa. For more details how to create and use scores, see the tutorial on How to add a score
The goal of this tutorial is to integrate this database into the TDP platform, such that it can be used in a later step for example to create a ranking view, see How to create a ranking view and other views.
¶ Create a backend library plugin
In How to create a new view plugin you learned how to create a frontend library plugin using yo phovea:init-lib. To create a backend library plugin, a server library or short slib, you can use corresponding generator.
# switch to the workspace directory
cd <workspace directory>
mkdir myserverlugin
cd myserverplugin
yo phovea:init-slib
Expert knowledge
It is possible to create a frontend and backend hybrid plugin using:
yo phovea:init-lib-slib
Similar to the client plugin, the generator prompts for a couple of questions. First, which modules this plugin requires. By default the phovea_server module is selected. Deselect it using space and use the arrow keys to find and select tdp_core. Second, whether any other external libraries should be included. For now, we can skip this section. Then a couple of question about the name, author, … of the plugin, similar to the frontend plugin. In the end, you should have entered a similar response:
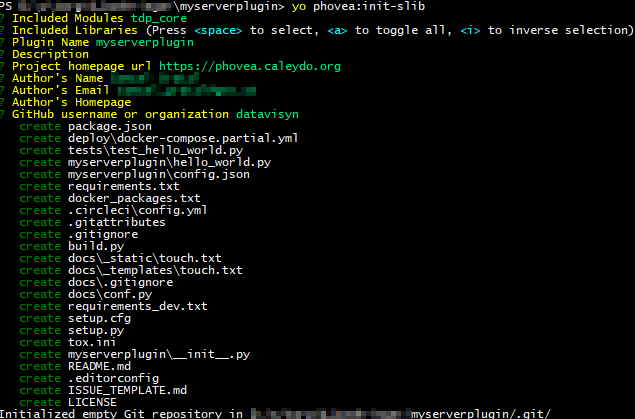
The created folder structure of a backend plugin is as follows:
┣━ Root folder (e.g. myserverplugin)
┃ ┣━ deploy
┃ ┃ ┣━ docker-compose.partial.yml
┃ ┣━ docs
┃ ┣━ myserverplugin
┃ ┃ ┣━ __init__.py
┃ ┃ ┣━ config.json
┃ ┃ ┣━ hello_world.py
┃ ┣━ tests
┃ ┃ ┣━ test_hello_world.py
┃ ┣━ docker-packages.txt
┃ ┣━ package.json
┃ ┣━ README.md
┃ ┣━ requirements.txt
Other files that are not listed in this listing are automatically generated and usually don’t need to be edited. myserverplugin is structured as follows:
- directory
myserverpluginthat contains the python package similar to thesrcdirectory in the in the frontend plugin.__init__.pyis the backend equivalent ofphovea.jscontaining the list of registered extensions of this plugin.config.jsonis a configuration file that can be used to customize this plugin. The content of this file is used as the default value. However, using the global phoveaconfig.jsonfiles, individual values can be overridden. In this example, it is used to specify the database location, making it easier to change later, especially in server environments.hello_world.pyis the default sample plugin registering an additional REST API namespace available at/api/hello_world. - directory
testscontains test code and can be executed using py.test. By convention test files have the prefixtest_. docscontain api documentation generated using Sphinx.deploydirectory contains thedocker-compose.partial.ymlfile which is a partial docker-compose file that is merged with other partial files of other plugins during workspace creation to create a combined docker-compose.yml file. It is used to specify additional containers for the local development environment, such as local test databases (for more information visit Docker Compose Docs). Docker will generate a seperate network for each docker compose configuration, so that a communication between the containers is possible. Please take care of your iptables and ip-forward configuration (https://docs.docker.com/engine/userguide/networking/default_network/container-communication/#communicating-to-the-outside-world). The container can communcate with the docker service name as DNS name (for example api, web, db) and the given port:<Service-Name>:<Port>package.jsonis the main description file, while in Python the notion of package.json is not known, it is used as a common description file for plugins.requirements.txtcontains a list of PyPi dependencies that are required by this plugin.docker-packages.txtis a list of Debian packages that can be installed within the Docker image using apt. However, installing additional Debian packages should be avoided when possible.
Don’t forget to commit your work!
¶ Create a DB connector extension
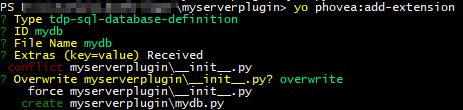
cd myserverplugin
yo phovea:add-extension
The type of the extension is: tdp-sql-database-definition. The id: mydb, as filename please use: mydb. Additional configuration elements are:
configKey=myserverplugin
In the end the resulting dialog should look like:
In addition, a file: mydb.py is created and the __init__.py is changed to:
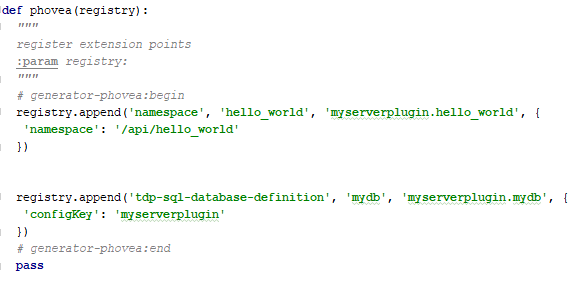
The first entry is as mentioned the hello world REST api namespace. In case of multiple plugins, don’t forget to delete this entry. The second one is the newly created one. The first argument is the extension point, the second the unique id, followed by the python module (without .py) that is implementing this extension point. The additional configKey attribute specifies that additional configuration for this database connector is available under the prefix: myserverplugin. During runtime that results in the config.json file content in the myserverplugin folder.
Now for implementing the DB connector extension, replace the content of the following files with the associated snippet.
config.json:
{
"dburl": "sqlite:///${phovea_server.absoluteDataDir}/mydb.sqlite",
"statement_timeout": null
}
We define default configuration option for the myserverplugin. By convention the database url is named dburl. The database url has to follow the SQLAlchemy engine configuration URL format. In this example we use the variable phovea_server.absoluteDataDir that is resolved to the _data directory at runtime.
myserverplugin.mydb.py
from tdp_core.dbview import DBViewBuilder, DBConnector, add_common_queries, inject_where
# idtype of our rows
idtype = 'MyIDType'
# columns of our mytable, it is used to verify dynamic parameters
columns = ['name', 'cat', 'value']
# main dictionary containing all views registered for this plugin
views = dict()
# register the view for getting the mytable itself
views['mytable'] = DBViewBuilder().idtype(idtype).table('mytable') \
.query("""SELECT my_id as id, * FROM mytable""") \
.derive_columns() \
.column('cat', type='categorical') \
.assign_ids() \
.call(inject_where) \
.build()
# notes:
# by convention the 'id' column contains the identifier column of a row
# derive_columns ... try to automatically derive column and column types
# column(column, attrs) ... explicitly set a column type
# assign_ids ... the tdp server should automatically manage and assign unique integer ids based on the 'id' column
# .call(inject_where) ... utility to inject a where clause that is used for dynamic filtering
# create a set of common queries
add_common_queries(views, 'mytable', idtype, 'my_id as id', columns)
def create():
"""
factory method to build this extension
:return:
"""
connector = DBConnector(views)
connector.description = 'sample connector to the mydb.sqlite database'
return connector
The last method create is the factory method for creating an extension instance. We create a DBConnector instance given a dictionary of views and return this instance. View definitions are created using the DBViewBuilder. The DBViewBuilder follows the Builder design pattern, thus all functions can be chained and the last call has to be .build() to build the actual view instance. The add_common_queries method defines a set of standard views based on the given table name.
¶ Updating the api server
In order to enable the new backend plugin on the server side, we have to update the workspace. In addition, if additional requirements or packages should be installed, the api docker container has to be rebuilt
cd <workspace directory>
yo phovea:update
docker-compose build api
docker-compose up -d
¶ Testing our DB connector
So far, there are no views that utilize our new db connector. See for example How to create a view. However, the REST api should be ready.
http://localhost:8080/api/tdp/db/ should now contain an additional entry:
{
"description": "sample connector to the mydb.sqlite database",
"name": "mydb"
}
Accessing the list of views via http://localhost:8080/api/tdp/db/mydb/ results in a JSON file describing the following views
- mytable … as manually defined
- mytable_single_score … as manually defined
- mytable_items … utility query for autocompletion purposes
- mytable_items_verify … utility query to verify the given input to valid items
- mytable_unique_all … utility query to return a set of unique column values such that it can be used in a select box
- mytable_unique … a combination of _items and _unique_all for autocompletion purposes
http://localhost:8080/api/tdp/db/mydb/mytable returns our table with records of the following format
{
"_id": 0,
"id": 1,
"name": "My 1",
"value": 372,
"cat": "MyCat 4",
"my_id": 1
}
¶ Custom Callback
In some cases, specifying a query is not enough to do the task. Certain aggregations aren’t possible with plain SQL. While the SQL query approach is favoured TDP allows to alternatively specify a callback function that is responsible for loading the data. However, all other methods are valid and needed, such as column, arg, and filter. They are used to validate the request and provide metadata about the result. The following example adds a callback view to our list of existing views but providing a callback function instead of a SQL query.
myserverplugin.mydb.py
from tdp_core.dbview import DBViewBuilder, DBConnector, add_common_queries, inject_where
# main dictionary containing all views registered for this plugin
views = dict()
# ...
def custom_callback(engine, arguments, filter):
"""
custom query implementation
:param engine: the SQLAlchemy engine
:param arguments: a dictionary of valid arguments
:param filter: a dictionary of valid filter key:value[] entries
:return: an array of dictionaries
"""
import pandas as pd
data = pd.read_sql("""SELECT cat, value FROM mytable""", engine)
grouped = data.groupby('cat').sum()
return grouped.to_dict('records')
views['callback'] = DBViewBuilder() \
.callback(custom_callback) \
.build()
def create():
# ...
The callback function is used to provide the callback instead of the query function to specify the SQL query. The callback function has to have the following signature:
engine
a SQLAlchemy engine instancearguments
A dictionary of the validated known arguments specified using the.arg(‘arg1’)syntax, such asdict(arg1=5). In SQL queries they are referenced using the colon syntaxcat = :arg1.filters
A dictionary of filters that should be applied. In TDP filters will be used to generate dynamic where clauses. Valid filter keys are defined using the.filter(‘cat’)syntax. Note that each value in the filters dictionary is a list by default with a length >= 0. E.g.dict(cat=[‘cat1’], value=[5])ordict(cat=[‘cat1’, ‘cat2’]). The former would result in an SQL query clause likewhere cat = ‘cat1’ and value = 5while the latter inwhere cat in [‘cat1’, ‘cat2’].- returns
The callback function has to return a list of dictionary objects to match the SQL query output. The pandas.to_dict('records')function can be used for this purpose.
¶ Database connector extension
A common case is that different plugins wanna access the same database but provide custom views. While individual DB connectors can be defined it is more inefficient since an SQL connection is created for each of them. To share the SQL connection accross DB connectors a different extension point is used: tdp-sql-database-extension. From an implementation point of view there is no difference to the previous one in createin views and so on. The only difference is that during the creation of the extension point a different configuration is needed:
base=mydb
where mydb refers to the extension id of the base DB connector. As a result the same SQLAlchemy engine will be shared between both DB connectors.
¶ Conclusion
Lessons learned:
- How to create a backend library plugin (server library, slib)
- How to define a backend extension point
- How to register a new database connector to TDP
- How to use a callback function instead of providing a SQL query